



 Follow Us
Follow UsProbabilistic Classifications of Unresolved Point Sources in PanSTARRS1 ("PS1-PSC")
Tachibana & Miller 2018 PASP 130 994Introduction |
Description of Data Products |
Data Access |
Github Repository |
Download README |
Introduction
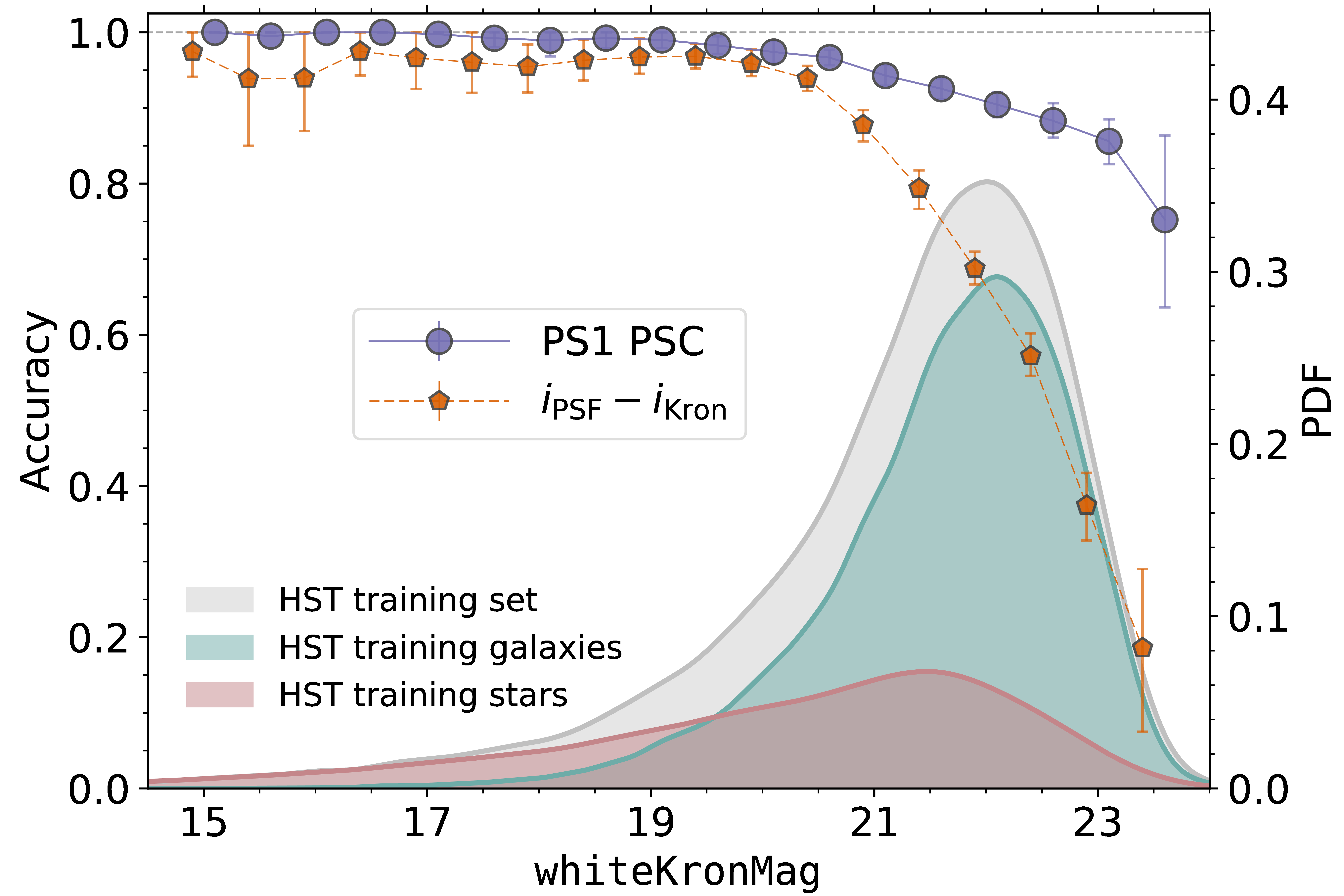
Classification accuracy as a function of brightness for the PS1-PSC. The accuracy is measured via 10-fold cross validation applied to ~40k sources in the COSMOS field with morphological classifications from the Hubble Space Telescope (HST). The filled purple circles show that the PS1-PSC is >90% accurate down to 22 mag, and >80% accurate to 23 mag. PS1-PSC classifications significantly outperform classifications made from a single cut on i_PSF - i_Kron > 0.05 (shown in dark orange pentagons), especially at the faint end. The relative distribution of point sources ("stars") and extended sources ("galaxies") is shown via Gaussian KDE estimates of the PDF of each via the filled shapes at the bottom of the figure.
Description of Data Products
The PS1-PSC data release consists of a catalog stored in the "HLSP_PS1_PSC" context within MAST CasJobs. The pointsource_scores table contains the PS1 object identifiers (objid) and the machine learning score (ps_score) computed by Tachibana & Miller 2018, where a score of 0 corresponds to extended sources and 1 corresponds to point sources.Data Access
MAST CasJobs
The primary way to interact with the PS1-PSC data is using MAST CasJobs which allows for SQL queries and the ability to cross-match the PS1-PSC classifications against other large catalogs in MAST CasJobs, such as PanSTARRS DR1. See the PanSTARRS CasJobs landing page and the PanSTARRS Data Archive page for more information and references.
Sample CasJobs Queries
The PS1-PSC catalogs are stored in the HLSP_PS1_PSC database in the pointsource_scores table, as well as two Views combining these classifications with columns in the PanSTARRS_DR1 database, such as sky positions. One View (pointsource_features_view) includes the measurements used by Tachibana & Miller 2018 to generate the classification feature inputs, and the other View (pointsource_magnitudes_view) includes columns of common magnitudes and errors.
| Example PS1-PSC Catalog Query | 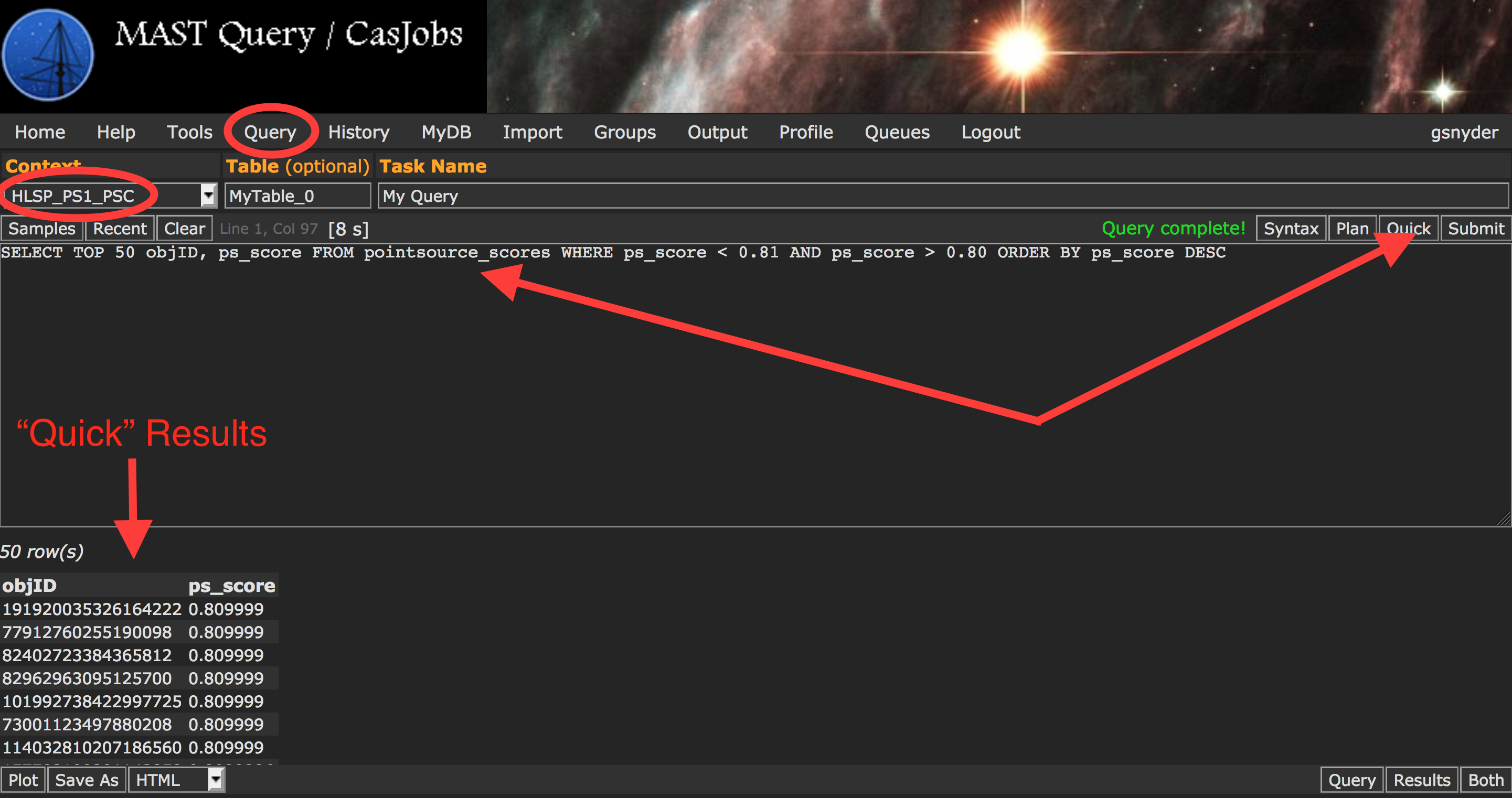 |
From the "Query" tab, select "HLSP_PS1_PSC" from the Context drop-down menu. You can then enter your query. In this example, we are doing a simple query to get a subset of unique object ID numbers and point source classification scores. For short queries, like this one, that execute in less than 60 seconds, you can hit the "Quick" button and the results of your query will be displayed below, where you can export them as needed. For longer queries, you can select into an output table (otherwise a default like MyDB.MyTable will be used), hit the "Submit" button, and when finished your output table will be available in the MyDB tab. | Perform a box search | 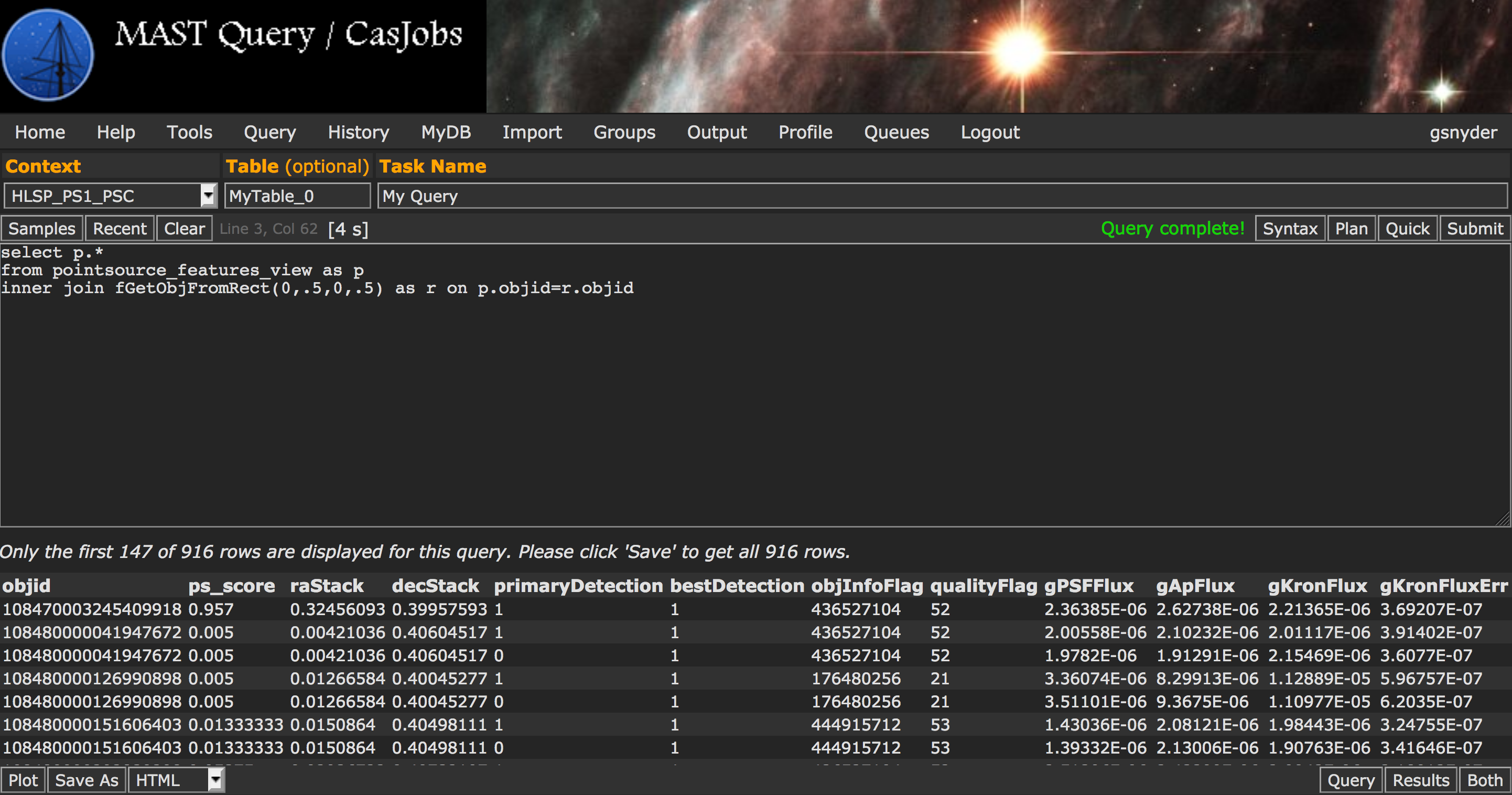 |
select p.* from pointsource_features_view as p inner join fGetObjFromRect(0,.5,0,.5) as r on p.objid=r.objid |
| Perform a cone search | 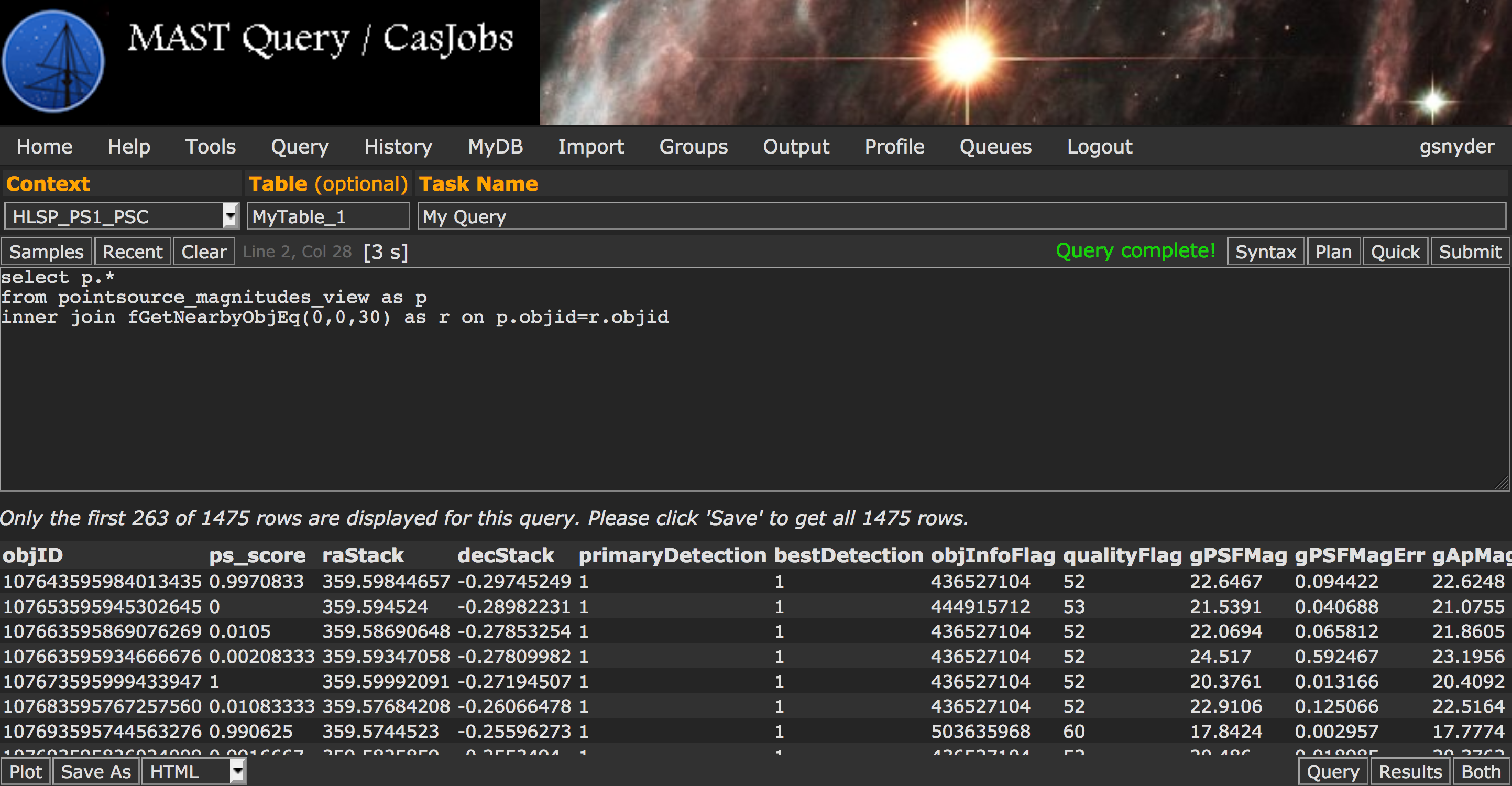 |
select p.* from pointsource_magnitudes_view as p inner join fGetNearbyObjEq(0,0,30) as r on p.objid=r.objid |
Direct Download
You can also download the PS1-PSC data in FITS or HDF5 format, where the catalog has been divided into 122 separate files sorted into 1-degree strips of declination. The filename structure is:| Format | Number of Files | File Structure | Example Download script |
|---|---|---|---|
| FITS | 122 | Binary table in first extension, metadata in primary extension. Python example with numpy and astropy.io.fits:
import numpy
import astropy.io.fits as fits
with fits.open('hlsp_ps1-psc_ps1_gpc1_0_multi_v1_cat.fits') as F:
print(F.info())
print(F[0].header.cards)
objid=F[1].data['objid']
ps_score=F[1].data['ps_score']
|
wget -v -nH -np https://archive.stsci.edu/hlsps/ps1-psc/hlsp_ps1-psc_ps1_gpc1_0_multi_v1_cat.fits |
| HDF5 | 122 | Python example with numpy and h5py:
import numpy
import h5py
with h5py.File('hlsp_ps1-psc_ps1_gpc1_0_multi_v1_cat.h5','r') as F:
list(F['d1'].keys())
list(F['d1']['block0_items']) #column 1 name
list(F['d1']['block1_items']) #column 2 name
objid=F['d1']['block0_values'].value
ps_score=F['d1']['block1_values'].value
|
curl -O https://archive.stsci.edu/hlsps/ps1-psc/hlsp_ps1-psc_ps1_gpc1_0_multi_v1_cat.h5 |
|
|
|